
Machine learning
Een van de doelstellingen van Industrie 4.0 is te komen tot intelligente machines – machines die zich zonder menselijke tussenkomst kunnen aanpassen aan wijzigingen in hun omgeving en daardoor ook uit zichzelf steeds performanter worden. De technologie die dat mogelijk moet maken komt uit de IT-wereld en heet Machine learning. Maar wat is dat eigenlijk?
Machine learning is een populaire term die vaak gebruikt wordt in combinatie met Big Data. Het is het werkveld van de Data Scientists – een nieuwe generatie wizz kids die zich in een alternatief universum lijken te begeven. Of toch in ieder geval in een universum waar een taal gesproken wordt die voor buitenstaanders nauwelijks verstaanbaar is.
Die mysterieuze taal draagt er toe bij dat de Data Scientist door Harvard Business Review uitgeroepen werd tot ‘Sexiest job of the 21st century’. Indien de wizz kids het gewoon zouden hebben over lineaire regressie of de stelling van Bayes, zou de aantrekkingskracht van hun job een flink stuk minder zijn.
Met andere woorden, de beoefenaars van machine learning hebben er alle belang bij om het mysterie rond wat ze doen, in stand te houden. Het succes weze hen gegund, natuurlijk. Maar laat ons toch eens even kijken onder de motorkap, naar wat er precies met machine learning bedoeld wordt.
Drie types van machine learning
Machine learning slaat op het gebruik van modellen en algoritmes waarvan de parameters bepaald worden door te leren uit data en/of ervaring. In het vakgebied worden drie soorten van dergelijke modellen en algoritmes onderscheiden, met elk hun eigen toepassingsgebied.
Het eerste type heet supervised learning, wat typisch gebruikt wordt in toepassingen waarbij een algoritme op basis van een input (x) een bepaalde output (y) moet geven. Het algoritme is in wezen een functie (of een beslissingsboom) waarbij machine learning tot doel heeft de parameters in deze functie te bepalen. Ook classificatie behoort tot dit type machine learning. De output is dan de klasse waartoe een bepaalde dataset behoort.
Bij unsupervised learning gaat het om data zonder input/output-relatie. De opdracht is dan om bepaalde structuren terug te vinden in grote hoeveelheden data. Een voorbeeld is wat Netflix doet om haar leden suggesties te geven over films en series die ze allicht willen zien. Ook Amazon gebruikt deze methode om u producten voor te stellen waarvan zij menen te weten dat u ze wilt kopen. Belangrijke opmerking hierbij is dat deze twee toepassingen ook als classificatie opdrachten opgevat kunnen worden, waarbij dan algoritmes voor supervised learning gebruikt worden.
De derde methode in machine learning heet reinforcement learning. Het is de meest intelligente vorm van machine learning omdat ze los komt van vooraf gedefinieerde functies en algoritmes. In de plaats daarvan laat men een machine – voor dit soort toepassingen komt men al snel bij neurale netwerken – via trial & error zoeken naar de ideale manier om een bepaald doel te bereiken. Een mooi voorbeeld hiervan is Neuraal netwerk leert bin picking.
Lineaire regressie
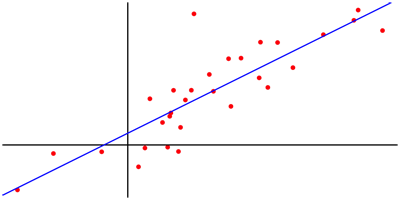
Lineaire regressie is uiteraard slechts voor een beperkt aantal toepassingen mogelijk, maar de methode kan eenvoudig uitgebreid worden door meer complexe functies met dan ook meer parameters te gebruiken.
Een speciaal geval zijn nog de toepassingen met een binaire output (ja of neen), waarbij principes voor logische regressie of methodes uit de statistiek gebruikt worden.
Apriori algoritme
Ook de methodes die in unsupervised learning gebruikt worden, zijn vaak een stuk minder complex dan de omschrijving doet vermoeden. De voorbeelden die we eerder aanhaalden van Netflix en Amazon kunnen bijvoorbeeld gerealiseerd worden met een methode die het Apriori algoritme genoemd wordt. Men kijkt dan naar de beschikbare data en telt hoe vaak bepaalde associaties zich voordoen. Als van 1000 mensen die naar House of Cards gekeken hebben, 400 mensen ook naar Orange is the new Black gekeken hebben en slechts 200 ook naar Narcos, zal men iemand die House of Cards bekeek, eerder Orange is the new Black aanraden.
In een tweede stap wordt ook rekening gehouden met de populariteit van de reeksen op zich. Bovenstaand voorbeeld kan immers meer zeggen over de populariteit van de genoemde reeksen, dan over de associatie in voorkeur. Daarom wordt de frequentie waarin een combinatie zich voordoet gedeeld door de absolute waarden waarin de individuen zich voordoen om de associatie meer betekenis te geven. Concreet: als Narcos in absolute termen een grootte-orde minder vaak bekeken wordt dan Orange is the new Black, wordt de combinatie House of Cards – Narcos plots relevanter dan de combinatie House of Cards – Orange is the new Black, en zal de Netflix klant die House of Cards bekeek, eerder Narcos aanbevolen krijgen.
Verbanden zoeken in data
Wat deze voorbeelden illustreren is dat machine learning in de meeste gevallen minder spectaculair is dan de term doet vermoeden. Het gaat in de praktijk immers veelal om het toepassen van gekende principes uit de wiskunde en statistiek.
Toch zit er in machine learning een principe dat behoorlijk revolutionair is, zeker in industriële toepassingen. Daar wordt al langer gebruikgemaakt van wiskundige modellen van processen, bijvoorbeeld om simulaties te doen, maar die werden in het verleden meestal opgebouwd vanuit de wetten van de fysica. In machine learning is de link met die wetten niet langer noodzakelijk om vanuit datasets tot een wiskundig model te komen. Het is met andere woorden niet langer noodzakelijk om een proces te begrijpen om het te kunnen modelleren. Bovendien kan zo een abstract model dat via machine learning bekomen werd, ook nog eens nauwkeuriger zijn dan een klassiek model, precies omdat het via reële data tot stand gekomen is.
Een tweede (mogelijke) revolutie zit in de kracht van unsupervised learning om verbanden te zoeken in grote hoeveelheden data – ook verbanden die men vanuit de bestaande inzichten in processen niet zou verwachten. Op die manier kan machine learning nieuwe inzichten verschaffen met toepassingsmogelijkheden in bijvoorbeeld procesoptimalisatie en predictief onderhoud.
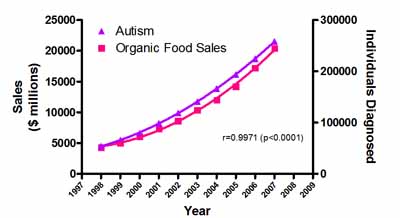
Een belangrijke opmerking hierbij is dat men het vaststellen van een correlatie niet mag verwarren met het bestaan van een oorzakelijk verband. Neem als voorbeeld de reële data uit bijgaande grafiek, waaruit een iets minder artificieel intelligente machine al snel de verkeerde conclusies zou kunnen trekken.
© Productivity.be, Tekst: Erwin Vanvuchelen
Feel free to share
Newsletter
Agenda
15/09 - 19/09: AMB, Messe Stuttgart (D)
24/11 - 26/11: SPS, Neurenberg (D)
23/02/27 - 26/02/27: Anuga FoodTec, Keulen
17/03/27 - 18/03/27: M+R, Antwerp Expo (B)
05/04/27 - 08/04/27: Hannover Messe, Hannover (D)
12/04/27 - 14/04/27: BEDEX, Brussels Expo (B)
14/06/27 - 18/06/27: ACHEMA, Frankfurt am Main (D)
22/06/27 - 25/06/27: Automatica, München (D)