
Deep learning
In de wereld van big data en artificiële intelligentie is er geen enkele technologie die meer tot de verbeelding spreekt dan deep learning. Via neurale netwerken slaagt men erin computers beoordelingen te laten doen zonder vooraf een algoritme te schrijven – een methode die vroeg of laat ook zijn weg zal vinden naar industriële automatisering.
Deze introductie tot deep learning past in onze artikelenreeks waarin ook artificiële intelligentie en machine learning uitgelegd worden. De drie termen zijn met elkaar verbonden, want machine learning is een methode om tot artificiële intelligentie te komen. Deep learning is op zijn beurt een van de mogelijke methodes binnen machine learning.
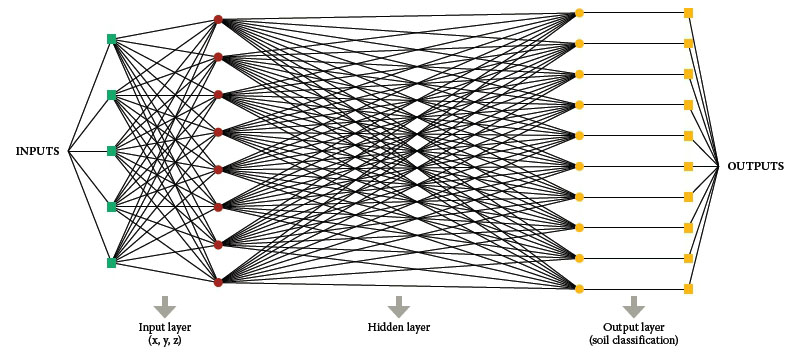
De term deep learning slaat op het gebruik van neurale netwerken. U weet wel, het simuleren van de werking van de hersenen via een netwerk van nodes die signalen aan elkaar doorgeven. Zo een artificieel netwerk is opgebouwd uit lagen waarbij de eerste laag nodes externe input krijgt. Elke node maakt een gewogen gemiddelde van zijn inputs (zie lineaire regressie) en geeft de output hiervan door aan de volgende laag. De gewichten in het gewogen gemiddeldes zijn een maat voor de relevantie van de bijhorende inputs voor de gewenste output. Vele lagen later (vandaar de deep in deep learning) komen de nodes tot een output.
Gelabelde data
Typisch aan zo een neuraal netwerk is wat in ons artikel over machine learning “reinforcement learning” genoemd wordt. Het systeem moet de parameters in de nodes zelf bepalen door training. Daarbij wordt het gevoed met grote hoeveelheden input, waarbij de parameters zichzelf aanpassen tot telkens de gewenst output bekomen wordt. De data die gebruikt wordt tijdens het trainen van het neuraal netwerk wordt gelabelde data genoemd. Het is een reeks van inputs waarvan telkens ook geweten is wat de output zou moeten zijn.
Neem als voorbeeld een specifieke uitdaging waar vandaag op gewerkt wordt in het kader van zelfrijdende voertuigen: het herkennen van verkeersborden. Om een stopbord te herkennen zou men in een traditionele applicatie werken met een algoritme dat bijvoorbeeld eerst de contouren zoekt in een beeld, vervolgens op zoek gaat naar een achthoek, dan kijkt of de kleur binnen die achthoek rood is, enz.
Het probleem met een dergelijke deterministische methode is dat ze het moeilijk heeft met de vele afwijkingen en onzekerheden die zich in de praktijk kunnen voordoen. Als er een struik naast een stopbord staat, bijvoorbeeld, met een tak die voor het bord in beeld komt, zal de camera niet langer een keurige achthoek zien en zal een deterministisch algoritme het moeilijk hebben om de achthoek te herkennen.
Een neuraal netwerk daarentegen zal tijdens zijn training nog andere borden zijn tegengekomen waar een tak voor stond. Het heeft dus al snel voldoende referentiepunten om het gedeeltelijk zichtbare bord alsnog als een stopbord te herkennen.
Convolutie
Dat beeldherkenning zo vaak wordt aangehaald als voorbeeld van deep learning is niet toevallig want de methode blijkt in de praktijk zeer doeltreffend te zijn voor deze toepassing. Ook in het analyseren van geluidssignalen voor spraakherkenning zijn neurale netwerken onklopbaar. Dat heeft alles te maken met het feit wat we net aanhaalden in de vorige paragraaf, namelijk dat de neurale netwerken door hun opbouw en manier van configureren (learning) op een heel organische manier omgaan met variaties.
Er is echter nog een zeer belangrijke tussenstap. De inputs voor beeldherkenning zijn in de meeste gevallen gewoon de pixels van het beeld die één op één worden ingevoerd in de nodes in de eerste laag van het netwerk. Dat houdt in dat die nodes een compleet andere input zouden krijgen als de camera een beetje verschoven wordt. Met andere woorden: het netwerk zou een stopbord dan alleen kunnen herkennen als het op precies dezelfde plaats staat als in de beelden waarmee het netwerk getraind werd.
Om dat op te lossen wordt aan de ingang van een neuraal netwerk een laag toegevoegd die de convolutielaag wordt genoemd. Dat principe wordt trouwens ook toegepast in klassieke beeldverwerkingsmethodes met deterministische algoritmes.
In de convolutie wordt een filter toegepast wat gezien kan worden als een kleiner kader waarmee men over het beeld beweegt. Op die manier kan de convolutielaag verschillende delen van een foto stap voor stap scannen om in elk frame op zoek te gaan naar wat een stopbord zou kunnen zijn. Het filter dat daarbij gebruikt wordt kan een deterministisch algoritme zijn maar zou even goed een kleiner neuraal netwerkje kunnen zijn.
De globale werking van het neuraal netwerk is dan dat in de convolutielaag gezocht wordt naar alle elementen die relevant kunnen zijn en dat die elementen vervolgens als input gebruikt worden voor de rest van het neuraal netwerk.
Voor het herkennen van personen, bijvoorbeeld, zoekt de convolutielaag eerst naar typische elementen zoals ogen, mond en oren, waarna de werking van het neuraal netwerk er min of meer op neerkomt dat het gaat kijken of er een match is tussen de gegeven combinatie en eerdere combinaties die het gezien heeft tijdens de training.
Voor de volledigheid voegen we hier nog aan toe dat de input bij beeldherkenning niet gewoon een frame is van x maal y pixels, maar dat het ook een diepte bevat voor de drie kleuren. Dat betekent dat dus ook de filters in de convolutie en het neuraal netwerk dezelfde diepte moeten hebben.
Testfase
Beeld- en spraakherkenning mogen dan wel de typische voorbeelden zijn maar een neuraal netwerk kan in alle soorten applicaties gebruikt worden als model voor machine learning. Het grote voordeel is dat men grote hoeveelheden gelabelde data – ongeacht hun betekenis – aan een netwerk kan voeden en zien wat het resultaat is. Uiteindelijk is zo een neuraal netwerk een haast oneindige aaneenschakeling van lineaire regressies wat inhoudt dat het in een groot aantal toepassingen wel een bruikbaar resultaat zal opleveren.
Dat het resultaat er bruikbaar uitziet, wil echter nog niet zeggen dat de output ook zinvol is. Net zoals een eenvoudige lineaire regressie de mist kan ingaan als men onvoldoende aandacht heeft voor de beperkingen van het model, is het ook gevaarlijk om op een neuraal netwerk te betrouwen als men per definitie nauwelijks kan opvolgen wat het model nu eigenlijk doet.
Een gedeeltelijke oplossing hiervoor is om slechts een deel van de gelabelde data te gebruiken bij het trainen van het netwerk. De overige gelabelde data, waarvan men dus de output op voorhand kent, kan dan gebruikt worden in een testfase om na te gaan hoe betrouwbaar de voorspellingen van het neuraal netwerk zijn.
Maar ook dan blijft het belangrijk om zich een beeld te vormen van het toepassingsgebied zodat men bijvoorbeeld weet in welke range van inputs het wel of niet betrouwbaar is.
Grafische kaarten
Dat deep learning pas de laatste jaren echt is komen opzetten heeft alles te maken met de enorme rekenkracht die ervoor nodig is. Om tot een intelligent systeem te komen is al snel een zeer groot aantal nodes nodig die bovendien ook nog eens met duizenden sets van inputs getraind moet worden.
Een doorbraak op het vlak van rekenkracht is er gekomen toen men krachtige grafische kaarten uit de gaming industrie begon te gebruiken die de eigenschap hebben dat ze berekeningen parallel kunnen uitvoeren. Producent NVIDIA is een van de koplopers in het domein en ontwikkelt intussen ook CPU’s die qua architectuur volledig afgestemd zijn op deep learning toepassingen.
Een voorbeeld hiervan is de NVIDIA DRIVE PX 2 computer die ontwikkeld werd voor onderzoek naar zelfrijdende auto’s. Het neuraal netwerk krijgt in dit geval de input van meerdere camera’s en sensoren. Door het systeem te trainen, wat concreet betekent dat men de computer laat mee volgen hoe een menselijke bestuurder rijdt, hoopt men dat het neurale netwerk zichzelf kan configureren tot een systeem dat ooit zelf het stuur zal kunnen overnemen.
Voor alle duidelijkheid: zo ver is men nog lang niet. De systemen waar vandaag wel al mee geëxperimenteerd worden, maken enkel gebruik van neurale netwerken in de eerder aangehaalde convolutie om elementen in de omgeving te herkennen waarna men deterministische algoritmes gebruikt om op basis hiervan beslissingen te nemen.
In de industrie wordt intussen ook al volop geëxperimenteerd met neurale netwerken, bijvoorbeeld voor het aansturen van robots en bij de ontwikkeling van zogenaamde soft sensoren die in staat moeten zijn om aan de hand van klassieke metingen in een proces een maat te genereren voor een niet direct meetbare grootheid zoals productkwaliteit. Men spreekt dan over ANFIS gebaseerde sensoren (Adaptive Neuro-Fuzzy Inference System).
© Productivity.be
Feel free to share
Newsletter
News
Amazon OpenSearch Service introduces Agentic Search
Delta Unveils the Delta D-Bot Robotics Platform at SPS 2025
New Compliance Test Tool Release for OPC UA V1.05.06
LAPP introduces its first UNITRONIC ACCESS remote I/O devices
Introducing the SLP-2000, SuperLight Photonics’ Full-Spectrum SWIR Laser Light Source
Agenda
25/11 - 27/11: SPS, Neurenberg (D)
04/02/26 - 06/02/26: Indumation.be, Kortrijk Xpo (B)
10/03/26 - 13/03/26: TechniShow, Jaarbeurs Utrecht
10/03/26 - 12/03/26: CFIA, Rennes
10/03/26 - 12/03/26: Embedded World, Nürnberg (D)
30/03/26 - 02/04/26: Global Industrie, Paris Nord-Villepinte (F)
20/04/26 - 24/04/26: Hannover Messe, Hannover (D)
06/05/26 - 07/05/26: Advanced Engineering, Antwerp Expo (B)
06/05/26 - 07/05/26: Chemspec Europe, Keulen (D)
19/05/26 - 21/05/26: Advanced Manufacturing, Antwerp Expo (B)
20/05/26 - 21/05/26: Food Tech Event, Brabanthallen, 's-Hertogenbosch (Nl)
15/09/26 - 19/09/26: AMB, Messe Stuttgart (D)
23/02/27 - 26/02/27: Anuga FoodTec, Keulen
17/03/27 - 18/03/27: M+R, Antwerp Expo (B)
14/06/27 - 18/06/27: ACHEMA, Frankfurt am Main (D)
22/06/27 - 25/06/27: Automatica, München (D)